Chapter Seven
Human-AI Collaborative NOVA
Corresponds to Section 5 of the paper
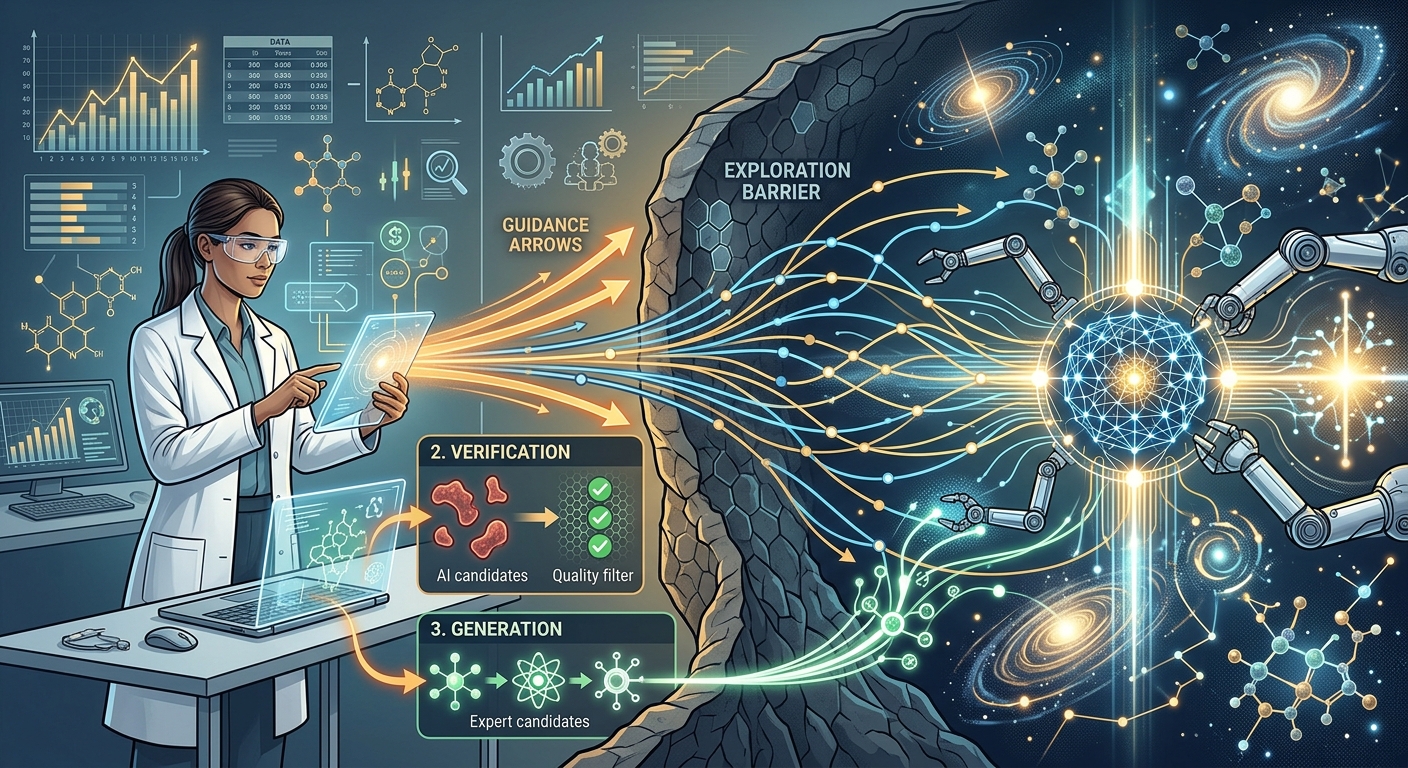
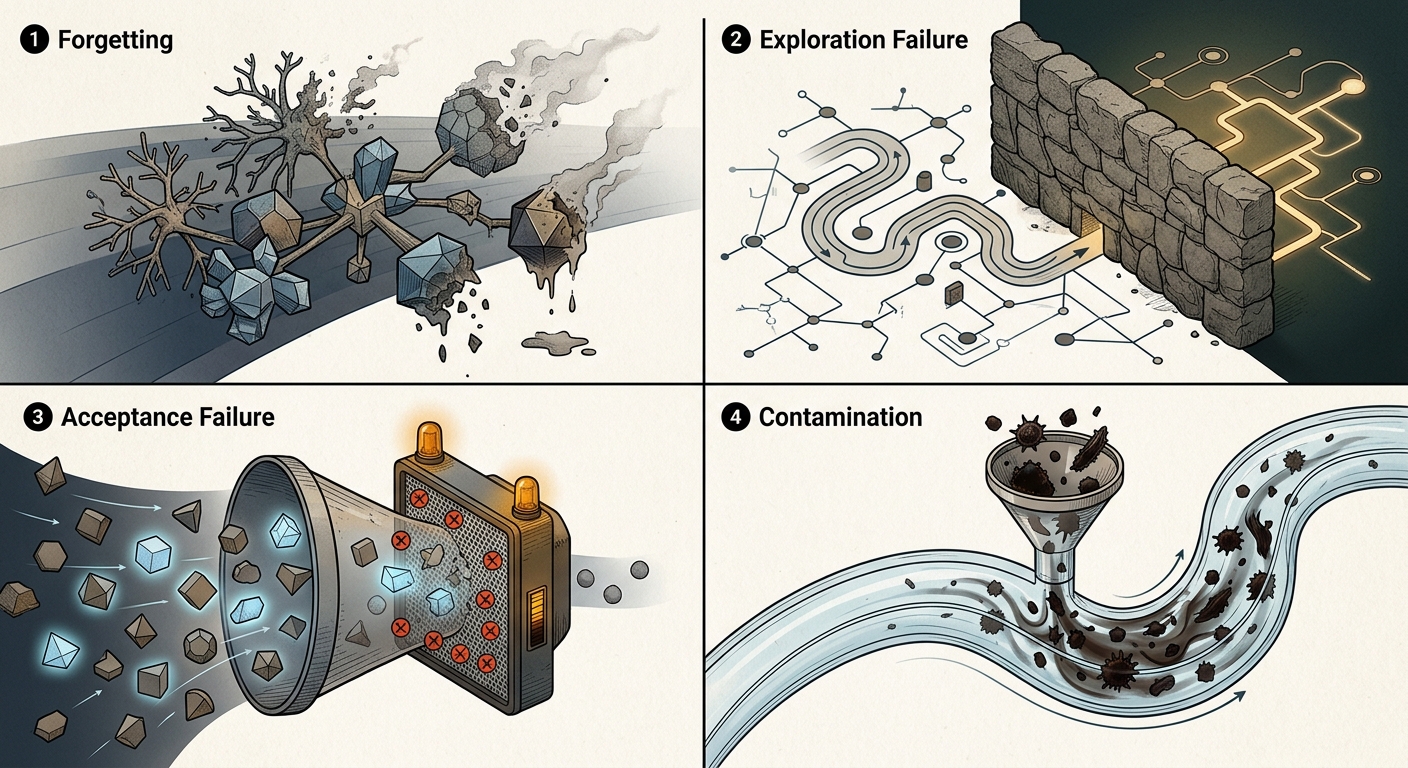
The preceding sections identify three barriers for autonomous NOVA: reachable support limits what can be discovered (Corollary 2), imperfect verification becomes more dangerous as new-valid mass shrinks (Corollary 4), and Zipf occupancy makes cumulative discovery costs grow superlinearly (Theorem 6). Human experts can intervene at each of these bottlenecks.
In the augmented NOVA loop, a human expert modifies \(Q_t\) to a guided distribution \(Q_t'\), the AI generates \(N_{\text{AI}}\) candidates from \(Q_t'\), the expert generates \(N_H\) candidates from their own distribution \(P_H\), and the combined candidates are verified.
Theorem 7
Sparse-Regime Human Amplification
In the sparse regime, the human amplification factor admits the first-order decomposition:
$$\boxed{A_H = A_{\text{guide}} \cdot A_{\text{verify}} \cdot A_{\text{gen}}}$$
where:
$$A_{\text{guide}} = \frac{M_t^{\text{new,guided}}}{M_t^{\text{new}}}, \qquad A_{\text{verify}} = \frac{r_{\text{eff},t}}{r_t}, \qquad A_{\text{gen}} = 1 + \frac{N_H\, \rho_{H,t}\, M_t^{\text{new},H}}{N_{\text{AI}}\, r_{\text{eff},t}\, M_t^{\text{new,guided}}}$$
Theorem 8
Human-Guided Support Expansion
If human guidance changes \(Q_t\) to \(Q_t'\) such that \(\mathcal{K} \cap \text{supp}(Q_t) \subsetneq \mathcal{K} \cap \text{supp}(Q_t')\), then the reachable valid set strictly expands. Hence guidance can break the autonomous exploration barrier.